
Introduction
In today’s fast-paced digital environment, staying ahead of the curve means leveraging real-time search insights to drive smarter decisions. Whether it's tracking brand visibility, conducting keyword research, or monitoring competitors, access to precise and up-to-date search engine data is critical.
Extracting valuable insights from today’s search engine result pages (SERPs)—especially from Google—has grown more challenging. With evolving features like featured snippets, knowledge panels, and dynamic carousels, effective Google Search Data Scraping demands more than basic techniques. Constant layout changes and advanced anti-bot mechanisms further complicate reliable data extraction.
This guide explores the expert-level tools and methodologies needed to Scrape Google Search Results effectively, even from the most dynamic and ever-shifting SERPs, in real-time and at scale.
Understanding the Rising Complexity of Extracting Data from Modern Search Interfaces
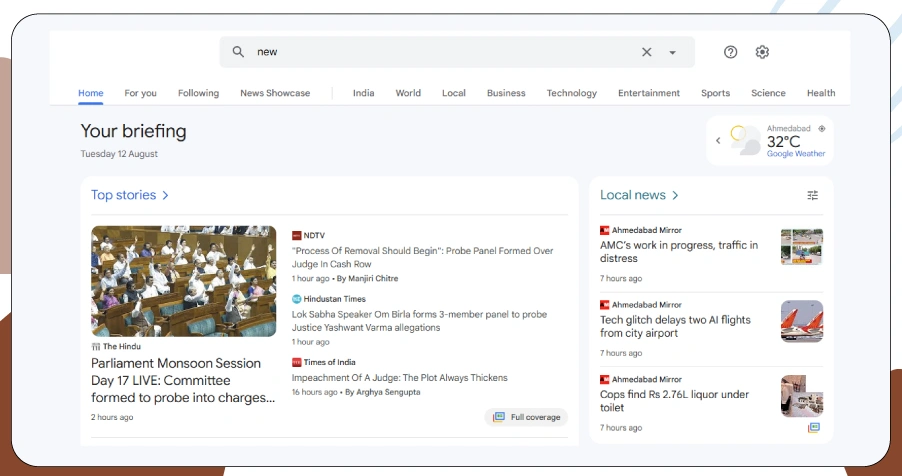
Google’s search results pages are no longer simple lists of links—they’re now dynamic, interactive, and tailored to deliver highly relevant experiences to users. This evolution, while great for usability, has made data extraction significantly more difficult for marketers, analysts, and developers alike.
Below are the core reasons why extracting data from today’s Google SERPs has become increasingly challenging:
JavaScript-Driven Content Delivery
Modern SERPs rely heavily on JavaScript to populate the majority of their content. This means that much of the valuable data is loaded only after the page’s scripts have fully executed. Standard HTML scrapers often fail to detect or retrieve this dynamically rendered information.
Constant and Unpredictable Layout Changes
Google frequently updates the structure and visual presentation of its search results to improve user experience. These regular layout changes can break scraping logic, requiring scrapers to be continually adjusted or rewritten to accommodate the new structure.
Advanced Bot Detection and Security Layers
Google employs sophisticated anti-bot mechanisms, including reCAPTCHA challenges, IP throttling, fingerprinting, and rate-limiting. Without proper rotation of IPs, user agents, and behavior mimicry, scraping attempts are often blocked or flagged.
Geo-Personalized Results
Search results are increasingly tailored based on the user’s geographic location, language, and search history. As a result, a query run from two different regions may return entirely different SERPs. To achieve consistency and accuracy, scrapers must replicate or manipulate geo-specific parameters effectively.
Diverse and Rich SERP Features
Modern SERPs are filled with structured elements such as featured snippets, video carousels, knowledge panels, top stories, shopping units, local business packs, and FAQ sections. Each of these components requires distinct parsing logic and increases the complexity of data modeling.
Due to these evolving barriers, traditional scraping approaches are no longer sufficient. Professionals aiming for Real-Time SERP Data Extraction must adopt methods beyond traditional HTML scraping, leveraging browser automation, headless rendering, rotating proxies, and smart data parsing strategies to stay effective.
Innovative Approaches for Navigating Search Result Page Complexities

Understanding and handling the dynamic nature of search engine results pages (SERPs) requires an innovative, flexible approach. With evolving structures, JavaScript-driven content, and anti-bot systems, extracting real-time data isn’t as simple as sending a basic HTTP request.
Professionals today rely on headless browser automation, intelligent data parsing, and advanced request handling to maintain accurate and consistent data collection. The Dynamic Content Scraping Tutorial plays a key role in understanding these modern techniques.
Let’s explore the core techniques to handle SERP complexity efficiently:
1. Execute JavaScript Using Headless Browsers
Google’s SERPs heavily rely on JavaScript to display essential content, such as featured snippets, ads, and dynamic results. Standard scrapers often miss this information.
Here's how professionals ensure complete data access:
- Deploy headless browsers like Puppeteer or Playwright.
- Simulate real user behavior to mirror natural browsing patterns.
- Wait for full page rendering before data extraction begins.
This method is critical to Scrape JavaScript-Rendered Search Pages, where traditional scraping approaches would otherwise fail.
2. Randomize Requests with User Agents and Proxies
Google's defenses are sophisticated and designed to Bypass Google Bot Detection. To maintain uninterrupted access:
- Utilize rotating proxies or residential IPs to appear as multiple real users.
- Randomize user-agent strings across sessions.
- Introduce delays and interaction behaviors that mimic human browsing.
This strategy significantly improves your ability to Scrape Google Search Results without triggering protective measures like captchas or IP bans.
3. Use Flexible Selectors and XPath Strategies
Even though Google's HTML structure is intentionally complex and ever-changing, it still follows specific patterns.
Experts craft resilient scraping scripts by:
- Identifying and tracking class names, tags, and DOM hierarchies.
- Mapping structured selectors to featured snippets, paid ads, and organic links.
- Building dynamic extraction rules that adapt as layouts evolve.
When applied correctly, these techniques help to Extract Search Result Data 2025 reliably across constantly shifting SERP designs.
4. Enable Intelligent Real-Time Query Management
To gain timely insights, it's essential to manage how and when your system interacts with the SERPs.
Real-time operations involve:
- Monitoring query frequency to prevent rate-limiting.
- Scheduling automated tasks for hourly or daily result tracking.
- Prioritizing trending topics or seasonal queries for immediate data pull.
By implementing this, teams gain the ability for Real-Time SERP Data Extraction, enabling agile decision-making in marketing, SEO, and competitive research.
Tools Experts Rely On for Real-Time Search Result Extraction
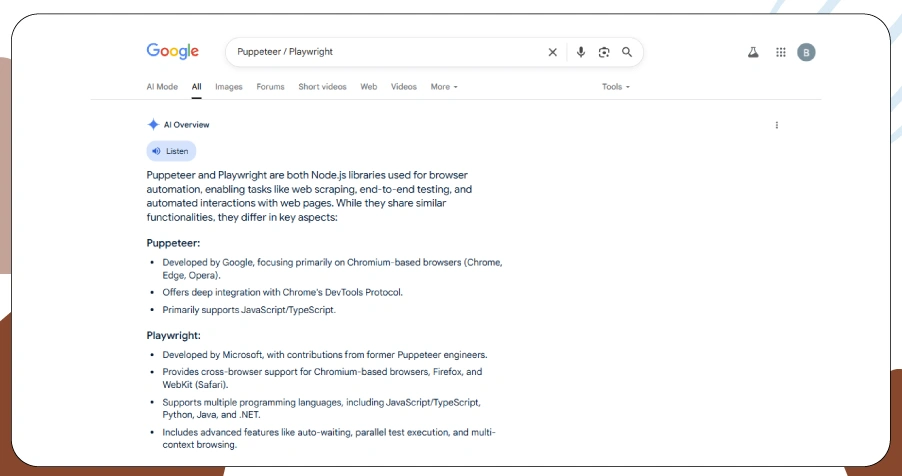
Achieving effective real-time scraping from dynamic search engine result pages requires more than just coding knowledge—it demands the right tools, smart configurations, and a deep understanding of how modern SERPs behave.
Below are some of the most reliable tools and frameworks professionals use for Google Dynamic SERP Scraping, each chosen for its strengths in handling dynamic content and minimizing detection:
- Puppeteer / Playwright: These headless browser automation libraries are ideal for complete browser-based scraping. With built-in JavaScript support, they allow precise interaction with dynamic pages, perfect for complex SERP structures.
- Scrapy + Splash: This combination brings together Scrapy’s efficient crawling capabilities with Splash’s JavaScript rendering, enabling smooth extraction from JS-heavy search result pages.
- Selenium WebDriver: While commonly used for testing, Selenium can also be a strong choice for smaller-scale scraping projects or real-time monitoring tasks, especially when custom interaction is needed.
- Browserless.io / ScrapingBee: These are cloud-based headless browser solutions that allow you to scale up scraping efforts while offloading infrastructure management. They’re well-suited for enterprise-level operations.
When these tools are configured alongside rotating proxies and responsible scraping practices, they become powerful assets to Scrape Google Search Results efficiently, without triggering rate limits or bans.
Navigating Challenges of Dynamic Search Result Pages with Smart Techniques

Scraping modern search engines isn't just about building a crawler — it's about outsmarting one of the most sophisticated detection systems on the web. From dynamic content rendering to aggressive anti-bot measures, several hurdles make real-time data extraction from dynamic SERPs a challenge.
Here’s how professionals overcome these barriers effectively:
- Maintain Persistent Sessions: By retaining cookies and session identifiers across multiple requests, the scraper can maintain continuity, making the interactions appear as part of a single human browsing session.
- Emulate Real User Behavior: Bots are easy to detect when they act like bots. By mimicking natural behavior, such as mouse movement, scrolling patterns, and random click paths, scrapers can blend in and avoid triggering security flags.
- Customize Headers and Render Client-Side JavaScript: Real browsers send specific headers and execute JavaScript on the client side. Mimicking this behavior, including injecting custom headers and rendering dynamic content through headless browsers, helps replicate a genuine user environment.
- Set Up Adaptive Monitoring Systems: Implementing real-time logging and alert systems allows scrapers to respond quickly to changes in SERP structures, CAPTCHA challenges, or other unexpected behaviors. This adaptability is essential for maintaining uptime and accuracy.
These advanced methods form the backbone of any high-performing Search Engine Result Page Scraper, enabling marketers, analysts, and researchers to extract reliable insights at scale, even from complex and dynamic search environments.
Unlocking Insights from Live Search Results: Why It Matters in 2025
In today's dynamic digital landscape, understanding how your business appears in real-time search results is critical for driving visibility, refining strategy, and maintaining competitive relevance. As Google’s algorithms evolve and become more personalized through AI, businesses need more innovative approaches to access, analyze, and act on this data as it happens.
Innovative methods to Scrape Google Search Results in real-time from dynamic SERP provide actionable insights that can fuel performance across multiple areas:
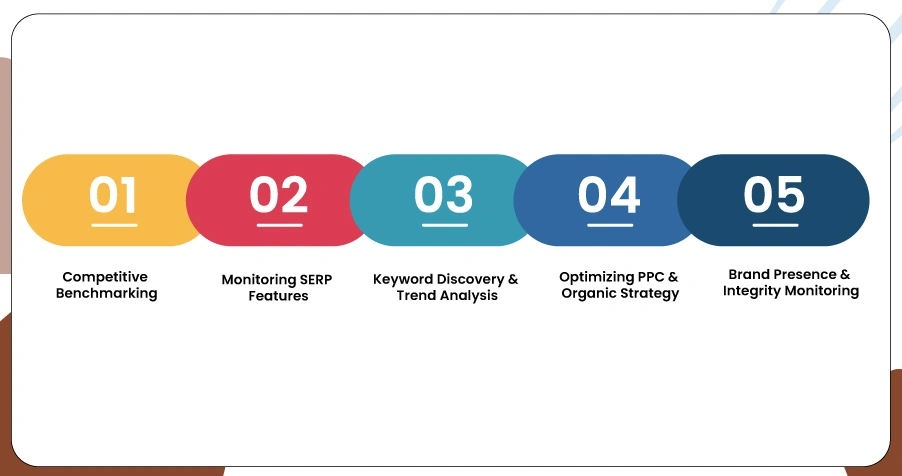
- Competitive Benchmarking:
- Track where your competitors rank for key queries.
- Uncover gaps or advantages in their SEO and content strategies.
- Identify which domains dominate high-value keywords in your space.
- Monitoring SERP Features:
- Stay informed when your brand appears in featured snippets, People Also Ask boxes, maps, carousels, or other SERP features.
- Gauge the frequency and positioning of these appearances to assess their impact on reputation and visibility.
- Keyword Discovery & Trend Analysis:
- Reveal high-potential keywords based on real-time shifts in Google’s results.
- Discover how intent is evolving and how Google is responding to it in SERP layouts.
- Optimizing PPC & Organic Strategy:
- Align paid ad strategies with real-time organic trends.
- Understand which keywords trigger both ads and organic results to avoid cannibalization and maximize ROI.
- Brand Presence & Integrity Monitoring:
- Detect unbranded mentions or competitor encroachment on brand-related queries.
- Identify possible content misrepresentations or misinformation in search listings.
By leveraging clever automation techniques to Scrape Google Search Results, businesses can continuously monitor, evaluate, and respond to shifts in the digital landscape.
With AI and personalization now deeply integrated into search engines, the ability to Extract Search Result Data 2025 is not just a technical advantage — it’s a strategic imperative.
How ArcTechnolabs Can Help You?
We offer tailored solutions designed to Scrape Google Search Results in real-time, even from complex and dynamically changing SERPs. Whether you need localized search data, competitor intelligence, or ongoing keyword performance tracking, our solutions are built for precision, adaptability, and scale.
Here’s how we help:
- JS-rendered SERP handling with headless browser technology.
- Captcha & bot detection Bypass with advanced evasion tactics.
- Geo-specific SERP targeting for localized insights.
- Adaptive scripts for changing layouts and features.
- Live data dashboards for tracking keyword performance.
- Scalable proxy management for high-volume scraping.
From agile scripts to enterprise-grade pipelines, we ensure your data extraction is seamless, secure, and reliable. If you’re looking for a robust and future-proof Search Engine Result Page Scraper setup, we’re ready to help.
Conclusion
As Google’s SERP continues to evolve with AI-driven results and complex structures, relying on outdated methods won’t deliver the insights you need. Modern businesses must adopt adaptive, intelligent techniques to Scrape Google Search Results efficiently and in real-time.
With us, you get the tools, technology, and support needed for seamless Google scraping With Headless Browsers that keep pace with every change. Contact ArcTechnolabs today to discuss your project or schedule a free consultation and unlock the full potential of live search data.







