
Introduction
Modern businesses rely heavily on web data to drive decisions, but the shift toward JavaScript-rendered pages has created major barriers for traditional scraping approaches. Handling JavaScript-Heavy Websites in Web Scraping has emerged as one of the most critical technical competencies for organizations seeking accurate, real-time data from complex digital platforms. We stepped in to bridge this gap, offering tailored solutions that go beyond conventional HTML parsing to extract data from fully rendered, client-side environments.
Many enterprises today operate data pipelines that were never designed to interact with dynamic front-end frameworks. With the rise of React, Angular, and Vue-based architectures, static scrapers frequently fail to capture meaningful content. Through Enterprise Web Crawling capabilities, we helped the client build a resilient infrastructure that could interact with JavaScript execution environments and return structured, clean data consistently.
The engagement began when a data-driven organization noticed significant gaps in the information collected from their target sources. Delayed renders, infinite scroll mechanisms, and AJAX-based content loading were causing incomplete datasets. We designed a solution architecture around Handling JavaScript-Heavy Websites in Web Scraping to resolve these failures and establish a dependable data collection pipeline that supported ongoing business intelligence requirements.
The Client
The client is a mid-sized technology and analytics firm operating across financial services, e-commerce intelligence, and market research verticals. Their internal teams depended on scraped datasets from competitor portals, product listing pages, and financial dashboards almost all of which are built on dynamic JavaScript frameworks. The volume and frequency of their data needs made manual collection entirely impractical.
With operations spanning multiple business units, they required a single integrated data feed that could support dashboards, pricing models, and competitive analysis tools simultaneously. Handling JavaScript-Heavy Websites in Web Scraping was not just a technical need, it was a strategic priority that would determine how quickly and accurately their teams could respond to market changes.
The client also needed Web Scraping Services that could scale without breaking when target websites introduced UI changes or additional JavaScript layers. Their previous vendor had failed to maintain consistent data quality after a major front-end redesign by one of their primary data sources. We took over with a more adaptive, browser-aware architecture designed to remain reliable even as target sites evolved over time.
Key Challenges
JavaScript-heavy websites present a range of technical obstacles that go far beyond what conventional scraping tools can manage. The client encountered several compounding challenges that slowed their data operations significantly:
- Inability to extract data from Single Page Applications (SPAs) that rely on asynchronous API calls and lazy loading
- Pages timing out or returning empty HTML because renderers couldn't wait for JavaScript execution to complete
- Frequent changes in DOM structures due to platform updates breaking existing scraper configurations
- Anti-bot protections including dynamic token generation, CAPTCHAs, and browser fingerprinting checks
- Difficulty in capturing infinite scroll content and modal-triggered data that never appeared in raw page source
- No unified pipeline for managing extraction across ten or more distinct JavaScript-based platforms simultaneously
- Absence of a monitoring layer to detect extraction failures or data gaps in near real-time
These challenges collectively made it impossible for the client to build a dependable data pipeline without specialized tooling and expertise in How to Scrape JavaScript-Heavy Websites Effectively.

Key Solution
We designed a multi-layered scraping architecture tailored specifically for JavaScript-rendered environments. Rather than relying on a single tool, the team combined browser automation, smart waiting logic, and adaptive parsing to extract clean, complete data regardless of how complex the target platform was.
- The foundation of this solution was Headless Browser Scraping in Heavy Dynamic Sites, where the team deployed Chromium-based headless instances capable of fully rendering pages just as a real user's browser would.
- This ensured that asynchronous API responses, lazy-loaded content, and dynamically injected DOM elements were all captured accurately.
- Web Scraping Using Selenium & JS played a key role in simulating real browser behavior; scrolling, clicking, waiting for element visibility, and interacting with dropdowns or filters before capturing the final rendered output.
- This approach was particularly effective for portal-style dashboards where data only appeared after a series of user interactions.
- Alongside browser automation, we integrated Web Scraping API Services to manage request routing, session persistence, and IP rotation reducing detection risks while maintaining extraction continuity across long scraping sessions.
This end-to-end architecture enabled Handling JavaScript-Heavy Websites in Web Scraping at a production scale, delivering reliable data feeds 24 hours a day without manual monitoring.

Data Points Extracted Across the Pipeline
Before the full solution architecture was finalized, we conducted a structured audit of all data points the client needed, the platforms they sourced them from, and the technical complexity involved in extracting each category. The following table captures the core data categories, associated platforms, and the scraping approach applied.
We mapped every extraction category to a specific technical method, ensuring that each data point was collected with maximum accuracy and minimum latency. This audit helped prioritize development effort and informed decisions around infrastructure sizing, proxy requirements, and render timeout configurations.
| Data Category | Source Platform Type | Scraping Approach | Render Complexity |
|---|---|---|---|
| Product Pricing & Availability | E-commerce Portals | Headless Browser with Wait Conditions | High |
| Financial Market Data | Dashboard Applications | API Interception + DOM Parsing | Very High |
| Customer Reviews & Ratings | Review Aggregators | Scroll Simulation + Lazy Load Handling | Medium |
| Search Result Pages | Search Engines & Directories | Rotating Proxies + Browser Emulation | High |
| News & Media Content | Editorial Platforms | Headless Fetch + Content Extraction | Medium |
Following the audit, we prioritized the highest-complexity categories first and built modular scraping agents for each. The structured approach allowed the client's engineering team to validate outputs in phases, reducing the risk of deploying an untested pipeline against production business workflows.
Advantages of Implementing ArcTechnolabs
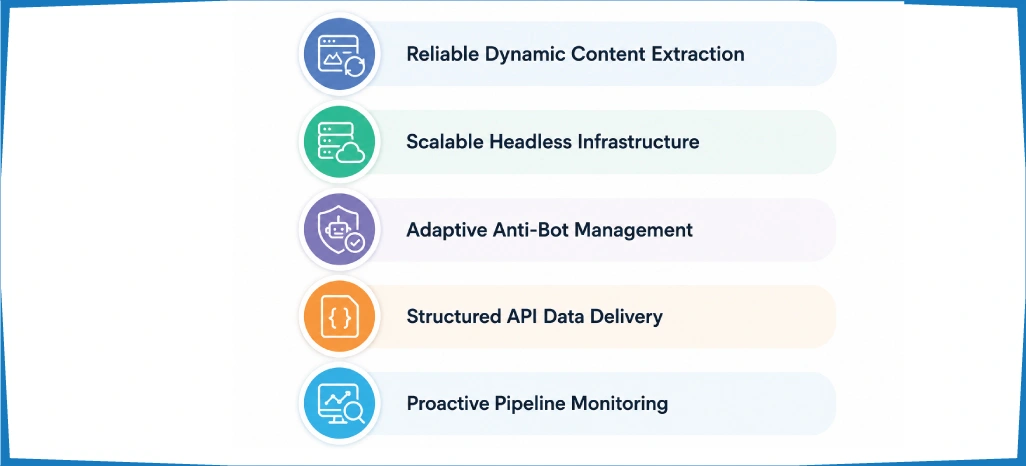
We brought measurable technical and operational advantages to the client's data infrastructure. Each benefit below reflects a core capability that directly addressed a gap in the client's previous setup.
-
Reliable Dynamic Content Extraction
We ensure complete data capture from JavaScript-rendered sources, eliminating gaps caused by Handling JavaScript-Heavy Websites in Web Scraping through browser-aware execution environments.
-
Scalable Headless Infrastructure
Distributed headless browser clusters power Headless Browser Scraping in Heavy Dynamic Sites, allowing concurrent extraction across dozens of sources without performance degradation or session conflicts.
-
Adaptive Anti-Bot Management
Intelligent fingerprint rotation and session handling overcome detection systems, ensuring How to Scrape JavaScript-Heavy Websites Effectively remains consistent even against sophisticated access-control mechanisms.
-
Structured API Data Delivery
Clean, normalized datasets are delivered through Web Scraping API Services, enabling direct integration with client dashboards, BI tools, and downstream machine learning pipelines.
-
Proactive Pipeline Monitoring
Continuous health checks and automated alerts through Mobile App Data Scraping Services ensure data delivery schedules remain uninterrupted even when target websites undergo structural or front-end changes.
Client's Testimonial
ArcTechnolabs fundamentally changed how we think about data collection. Their expertise in Handling JavaScript-Heavy Websites in Web Scraping solved problems we had been struggling with for over a year. The pipeline they built is stable, accurate, and scales exactly as our needs grow. The team's understanding of Headless Browser Scraping in Heavy Dynamic Sites gave us capabilities we simply didn't have before.
– Director of Data Engineering, Technology & Analytics Firm
Conclusion
Organizations that depend on web data cannot afford to let JavaScript complexity become a permanent blind spot in their intelligence pipelines. We specialize in Handling JavaScript-Heavy Websites in Web Scraping, transforming technically demanding extraction environments into structured, reliable data assets.
How to Scrape JavaScript-Heavy Websites Effectively is not a one-time fix; it is an ongoing discipline that requires adaptive architecture, continuous monitoring, and deep technical expertise. Contact ArcTechnolabs today to discuss your data extraction challenges and discover how our technical capabilities can turn complex web environments into consistent, high-quality data pipelines that power smarter business decisions.

