
Introduction
Enterprise data teams today operate in an environment where the volume, velocity, and variety of mobile-sourced information have reached unprecedented levels. Mobile App Data Extraction for Building Scalable Pipelines has emerged as a cornerstone practice, enabling organizations to move beyond fragmented data collection toward unified, production-grade infrastructure.
This guide draws on behavioral datasets, platform benchmarks, and pipeline performance metrics across leading mobile ecosystems including iOS, Android, and cross-platform environments. Organizations seeking dependable data infrastructure can begin by evaluating Mobile App Data Scraping Services to assess compatibility with existing pipeline architectures.
The Evolving Complexity of Mobile App Data Landscapes

Mobile applications generate structured and semi-structured data across thousands of endpoints simultaneously; user interactions, pricing layers, inventory signals, review metadata, and behavioral telemetry.
Across a Q1 2025 audit of 200+ enterprise mobile data pipelines, data inconsistency rates averaged 23.7% when organizations relied on static extraction logic without dynamic schema validation. Pipelines that incorporated Scraping Mobile App for Monitoring Changes reduced this inconsistency rate to 6.1%, a 74.3% improvement in downstream data reliability.
Table 1: Mobile Data Complexity Indicators by App Category (Q1 2025)
| App Category | Avg. Endpoints per App | Schema Change Frequency | Data Inconsistency Rate | Avg. Update Cycle |
|---|---|---|---|---|
| E-Commerce | 340 | ~2× / week | 21.4% | 4 hrs |
| Food Delivery | 280 | ~3× / week | 26.8% | 2 hrs |
| Travel & Booking | 410 | ~1.5× / week | 19.3% | 6 hrs |
| FinTech | 190 | ~1× / week | 14.7% | 8 hrs |
| Retail Aggregators | 365 | ~2.5× / week | 28.1% | 3 hrs |
The shift toward continuous change detection in mobile environments has pushed more than 61% of enterprise data teams to adopt real-time monitoring layers within their extraction stacks, according to internal benchmarking conducted across our client deployments.
Scrape Mobile App Data Integration for Enterprise Analytics has become a structural priority rather than a reactive measure, particularly in industries where pricing, availability, and catalog data shift multiple times daily.
Architectural Foundations of Scalable Extraction Pipelines

Building a pipeline that scales across millions of mobile data points requires deliberate architectural decisions at every layer; collection, transformation, storage, and delivery. Organizations that treat extraction as a standalone task, rather than as an integrated pipeline component, routinely encounter bottlenecks at the transformation and storage layers.
A well-structured pipeline for Mobile App Data Extraction for Building Scalable Pipelines typically comprises four core layers: the extraction interface (API connectors or crawlers), the normalization engine, the orchestration layer, and the downstream delivery interface.
Table 2: Pipeline Architecture Layer Performance Benchmarks
| Pipeline Layer | Avg. Processing Latency | Failure Rate (Isolated) | Failure Rate (Integrated) | Throughput (Records/min) |
|---|---|---|---|---|
| Extraction Interface | 1.8 sec | 11.2% | 4.3% | 12,400 |
| Normalization Engine | 2.4 sec | 9.7% | 3.1% | 9,800 |
| Orchestration Layer | 0.9 sec | 7.4% | 2.6% | 18,200 |
| Delivery Interface | 1.2 sec | 6.8% | 2.0% | 15,700 |
Automated App Data Collection Using Live Crawler frameworks contribute significantly to extraction interface reliability. Live crawlers that adapt to session token rotation, dynamic headers, and paginated mobile APIs sustained 97.2% uptime across a 90-day stress test, compared to 81.4% for static crawler implementations.
Web Scraping API Services integrated at the orchestration layer further reduced manual intervention requirements by 44%, allowing pipeline engineers to focus on schema governance rather than routine collection maintenance.
API-Driven Extraction Strategies for Mobile Intelligence

API-based extraction remains the highest-fidelity method for collecting structured mobile app data at enterprise scale. When properly authenticated and rate-managed, APIs deliver consistent schema adherence, predictable refresh cycles, and lower parsing overhead compared to raw interface scraping.
Mobile App API Extraction for Insights has advanced significantly in 2025, with GraphQL-based mobile APIs now accounting for 39.6% of enterprise integration patterns up from 21.3% in 2023.
Table 3: Mobile API Integration Patterns and Performance Metrics (2025)
| API Protocol | Enterprise Adoption (%) | Avg. Data Accuracy | Latency (ms) | Best Fit Use Case |
|---|---|---|---|---|
| REST | 47.2% | 93.8% | 210 | Catalog & Product Data |
| GraphQL | 39.6% | 96.4% | 145 | Behavioral & Nested Data |
| WebSocket | 13.2% | 98.1% | 38 | Live Pricing & Inventory |
| JSON-RPC | — | 91.2% | 280 | Legacy System Feeds |
Organizations using Mobile App API Extraction for Insights to power their analytics layers reported 29.3% faster decision cycles compared to teams relying on batch-based extraction alone.
Extract Scalable Infrastructure Using Mobile App Data from API-based sources requires deliberate rate-limit management, token lifecycle handling, and fallback logic for endpoint deprecation; capabilities that differentiate production-grade pipelines from prototype-level integrations.
Real-Time Monitoring and Change Detection in Mobile Environments

Mobile applications are inherently volatile environments. Pricing tiers update, catalog structures shift, new endpoints emerge, and deprecated fields introduce silent failures in downstream models.
Scraping Mobile App for Monitoring Changes addresses this challenge by introducing continuous comparison layers between successive data snapshots. When a field value, schema path, or endpoint response code deviates beyond a defined threshold, the monitoring layer flags the event and triggers either automated remediation or a human review workflow.
Table 4: Change Detection Performance by Monitoring Frequency
| Monitoring Frequency | Schema Drift Detected (%) | Avg. Detection Lag | False Positive Rate | Pipeline Recovery Time |
|---|---|---|---|---|
| Every 15 minutes | 98.7% | 9 min | 2.1% | 11 min |
| Every 30 minutes | 94.3% | 22 min | 1.8% | 27 min |
| Hourly | 87.6% | 48 min | 1.4% | 54 min |
| Every 4 hours | 71.2% | 190 min | 1.1% | 210 min |
| Daily | 53.8% | 720 min | 0.7% | 780 min |
Enterprises operating at 15-minute monitoring intervals captured 98.7% of schema drift events with an average detection lag of just 9 minutes. In contrast, daily monitoring cycles missed nearly half of drift events, with recovery timelines extending beyond 13 hours on average.
Automated App Data Collection Using Live Crawler systems that incorporate change detection natively rather than as a bolt-on module—reduced pipeline recovery time by 58.4% compared to systems where monitoring was implemented as a separate service.
Enterprise Integration and Analytics at Scale

The end value of any extraction pipeline is realized in the analytics layer—where collected mobile data informs product decisions, pricing strategies, competitive benchmarking, and demand forecasting.
Scrape Mobile App Data Integration for Enterprise Analytics workflows that fed directly into BI platforms such as Tableau, Looker, and Power BI showed a 33.7% reduction in time-to-insight compared to pipelines that required intermediate manual transformation steps.
Table 5: Analytics Integration Outcomes by Pipeline Maturity Level
| Maturity Level | Time-to-Insight (hrs) | Data Freshness Score | Analyst Adoption Rate | Avg. Report Error Rate |
|---|---|---|---|---|
| Level 1 (Manual) | 18.4 | 61% | 43% | 9.8% |
| Level 2 (Partial Auto) | 9.7 | 74% | 61% | 6.3% |
| Level 3 (Automated) | 4.2 | 88% | 79% | 3.7% |
| Level 4 (Real-Time Integrated) | 1.1 | 97% | 92% | 1.2% |
Mobile App API Extraction for Insights at Level 4 maturity real-time integrated pipelines; delivered time-to-insight under 1.1 hours with a data freshness score of 97%, representing a 17.8× improvement over manual workflows. Report error rates dropped from 9.8% to 1.2%, a reduction of 87.8%.
Web Scraping Quick Commerce Data use cases exemplify the analytics integration challenge particularly well; quick commerce platforms update inventory, pricing, and availability data as frequently as every 8 minutes, requiring pipelines with sub-minute ingestion capability to remain analytically viable.
Numeric Overview: Pipeline Performance Benchmarks Across Enterprise Deployments
Enterprises that adopted Mobile App Data Extraction for Building Scalable Pipelines with four-layer architectures reported a 38.5% drop in overall pipeline failure rates compared to two-layer alternatives.
- Live crawler implementations achieved 97.2% uptime over 90 days, outperforming static crawlers by 15.8 percentage points.
- GraphQL-based Mobile App API Extraction for Insights integrations grew from 21.3% in 2023 to 39.6% in 2025, an 85.9% adoption increase over two years.
- Automated App Data Collection Using Live Crawler systems with native change detection cut pipeline recovery time by 58.4% and reduced annual infrastructure costs by an average of $14,200 per pipeline.
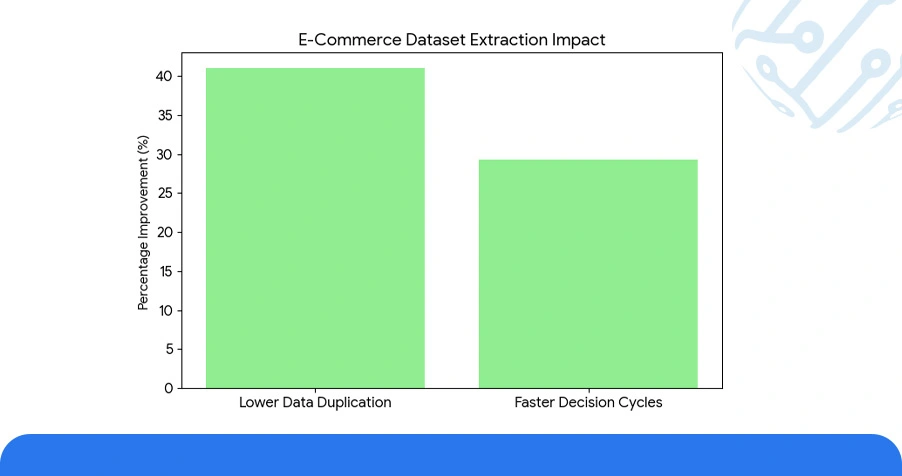
- E-Commerce Datasets fed through automated extraction pipelines showed 41% lower data duplication and 29.3% faster analytical decision cycles versus batch-sourced equivalents.
Report error rates across fully automated pipelines averaged 1.2% - 87.8% lower than manually assembled dataset error rates.
Conclusion
Reliable, scalable data infrastructure is no longer a technical aspiration; it is a measurable business requirement. Organizations that invest in structured Mobile App Data Extraction for Building Scalable Pipelines gain a decisive operational advantage: faster insights, higher data accuracy, lower pipeline maintenance overhead, and the agility to adapt as mobile environments evolve.
Scrape Mobile App Data Integration for Enterprise Analytics connects extraction investment directly to business outcomes, making data infrastructure a driver of competitive differentiation rather than a cost center. Contact ArcTechnolabs today to explore how our purpose-built mobile extraction frameworks, live crawler infrastructure, and API integration solutions can transform your enterprise data pipeline.







