
Introduction
In the ever-evolving digital ecosystem, metadata serves as the invisible blueprint behind every web page, defining its structure, purpose, and interaction. For SEO specialists, digital marketers, and data analysts, it offers an invaluable lens into the behavior and intent of online content. Mastering how to Scrape Website Metadata empowers teams to make smarter, faster, and more informed decisions across campaigns and platforms.
As we enter 2025, organizations are increasingly relying on intelligent Website Metadata Extraction 2025 strategies to unlock deeper personalization, ensure content relevance, and accelerate data-driven workflows. It's no longer optional—it’s foundational for any competitive digital strategy.
Decoding the Layers: Understanding What Website Metadata Includes

Before diving into specific techniques, it's essential to understand what website metadata includes and how each type serves a distinct analytical purpose. These metadata elements play a critical role in web visibility, content structure, and technical optimization:
- Meta Title & Description: These are fundamental for assessing how a webpage represents itself in search engine listings. They influence click-through rates and SEO visibility.
- Open Graph Tags: These tags define how content appears when shared across social media, playing a significant role in engagement and branding consistency.
- Schema Markup (schema.org): This structured data provides detailed context to search engines, enhancing visibility through rich snippets such as ratings, FAQs, and product information.
- Canonical URLs: These help search engines identify the primary version of a webpage, crucial for avoiding SEO penalties due to duplicate content.
- Language, Author, and Charset Tags: These tags offer technical insights into the content’s formatting, authorship, and language settings.
Ultimately, mastering the methods to Extract Meta Tags From Websites equips professionals with the ability to build more intelligent, search-optimized, and scalable digital environments.
Key Methods for Extracting Metadata Effectively
There’s no universal method for metadata extraction, but several proven techniques cater to different levels of need, from quick checks to high-scale automation. Below are some of the most effective and adaptable methods for extracting metadata with precision.
1. Manual Inspection for Quick Audits
For small-scale tasks or one-off SEO Metadata Scraping checks, manual inspection is a simple and immediate solution. This method is especially effective when working on quick audits or when analyzing a competitor’s metadata structure:
- Open the target webpage in your browser.
- Right-click and choose “View Page Source” or use “Inspect Element.”
- Search for <meta> tags, <title>, Open Graph data (og:title, og:description), or schema markup elements.
Though not suitable for large-scale use, this method provides an immediate snapshot of the metadata and helps validate what search engines and social platforms might see.
2. Browser Extensions for Lightweight Needs
When the need extends beyond manual checks but doesn’t yet require coding, browser extensions are a great intermediate solution. These tools help extract key metadata fields in real-time from any webpage without writing a single line of code.
Popular options include:
- Meta SEO Inspector: Great for visualizing meta tags, canonical links, and Open Graph data.
- OpenLink Structured Data Sniffer: Helps detect structured data formats, including RDFa, Microdata, and JSON-LD.
- Detailed SEO Extension: Provides a comprehensive overview of page titles, meta descriptions, H1 Headers, and more.
These tools make it easy to instantly Get Title And Description From URL, along with other core metadata elements, such as canonical tags and social media previews. Ideal for marketers, SEOs, and analysts managing small-scale metadata audits or quick client reporting.
3. Automating Metadata Collection with Custom Code
When scalability and flexibility are a priority, writing your metadata scraping scripts becomes the most powerful approach. For developers and data engineers, custom scripts allow you to handle multiple pages, apply filters, and transform raw HTML into structured insights.
Why it's effective:
- You can extract specific tags (e.g., meta description, Open Graph, schema.org).
- Handle error cases, redirects, and JavaScript-rendered content.
- Store and analyze metadata at scale for downstream applications.
Example: Python Script Using requests + lxml
import requests
from lxml import html
def extract_metadata(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
tree = html.fromstring(response.content)
title = tree.xpath('//title/text()')
description = tree.xpath('//meta[@name="description"]/@content')
keywords = tree.xpath('//meta[@name="keywords"]/@content')
og_title = tree.xpath('//meta[@property="og:title"]/@content')
og_description = tree.xpath('//meta[@property="og:description"]/@content')
return {
"Title": title[0] if title else None,
"Description": description[0] if description else None,
"Keywords": keywords[0] if keywords else None,
"Open Graph Title": og_title[0] if og_title else None,
"Open Graph Description": og_description[0] if og_description else None
}
# Example usage:
url = "https://example.com"
metadata = extract_metadata(url)
for key, value in metadata.items():
print(f"{key}: {value}")
This method enables you to Scrape Website Metadata from multiple URLs and scale across hundreds or even thousands of pages. You can customize the script to extract structured data, social metadata, language attributes, or even dynamically injected tags using headless browsers or Selenium.
Unlocking Deeper Web Insights Through Structured Metadata

As structured data becomes the standard for modern web content, Structured Metadata Collection has emerged as a powerful method to extract rich, contextual insights. These structured tags offer far more than just basic HTML meta tags—they provide access to key data elements, including:
- Product attributes, such as price, ratings, and availability.
- Details about events, including time, venue, and participants.
- Metadata on articles, including publication dates and author info.
- Local business essentials like store hours, addresses, and contact information.
This type of metadata is commonly embedded using formats such as JSON-LD, Microdata, or RDFa, all of which are standardized through schema.org. Efficiently Scraping schema.org Data empowers your team with highly organized and easily actionable datasets, crucial for content categorization, search optimization, and digital intelligence strategies.
Understanding Social Metadata for Optimized Sharing
Effective social sharing optimization starts with implementing the correct metadata. Platforms like Facebook and LinkedIn rely on Open Graph tags, while X (formerly Twitter) uses Twitter Cards to format previews.
Example Open Graph tags:
<meta property="og:title" content="Blog Title">
<meta property="og:description" content="Short summary">
<meta property="og:image" content="image.jpg">
For developers and digital marketers seeking to maintain consistent branding across multiple channels, Scraping Open Graph Tags offers valuable insights. It reveals how content is structured, how visuals and headlines are being pulled, and where inconsistencies might harm social engagement or brand alignment.
By analyzing these tags across competitor sites or your content at scale, businesses can fine-tune their approach to maximize exposure and improve their social media presence.
Scaling with the Right Tools
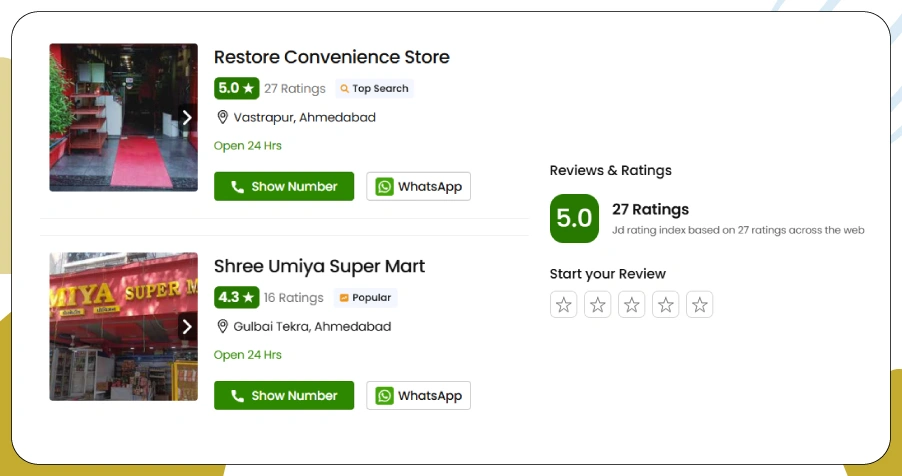
When operating at an enterprise level, manual processes quickly become inefficient. That’s where the power of Metadata Scraping Tools comes in—designed to streamline large-scale metadata extraction while maintaining accuracy and speed.
Here’s what the right tools should offer:
- Easy configuration to Get Title And Description From URL across thousands of pages.
- Support for schema extraction, meta tag parsing, and structured audits.
- No-code or low-code options for faster onboarding and ease of use across teams.
- Exportable results in formats like CSV or JSON for smooth integration into existing systems.
These capabilities ensure consistent performance, allowing teams to scale metadata extraction while maintaining high data quality and reducing operational friction.
Technical SEO and Metadata Monitoring

Adequate search visibility starts with metadata that aligns tightly with your SEO strategy. Through SEO Metadata Scraping, teams can actively monitor how their metadata performs and ensure technical elements remain optimized over time.
Key areas to monitor regularly include:
- Meta Titles and Descriptions: Ensure relevance, uniqueness, and keyword alignment to support better visibility.
- Hreflang Tags: Crucial for international sites, they help search engines serve the right content to the right users based on language and location.
- Canonical Tags: Prevent duplicate content issues and consolidate ranking signals across similar URLs.
Automated monitoring of these elements helps maintain technical SEO health, uphold brand consistency, and strengthen international SEO efforts. With frequent checks via scripts or APIs, businesses can quickly respond to metadata changes or errors before they impact rankings.
Challenges You May Face While Scraping Metadata

Although the benefits are clear, implementing metadata scraping comes with a set of challenges that must be addressed proactively:
- Dynamic Content: Websites that use heavy JavaScript often delay metadata rendering. Tools like Puppeteer or Selenium are required to handle such complexity effectively.
- Anti-Bot Measures: Some websites actively block scrapers using CAPTCHA systems, IP rate limits, or user-agent detection, making scraping efforts more difficult.
- Legal Compliance: It’s essential to operate within legal and ethical boundaries by adhering to each website’s terms of service and respecting robots.txt files.
To overcome these hurdles and maintain operational integrity, organizations should use a robust HTML Meta Tag Extractor with built-in proxy rotation, headless browser capabilities, and comprehensive error handling for smooth and scalable performance.
How ArcTechnolabs Can Help You?

We specialize in solutions that help businesses to Scrape Website Metadata with precision, scale, and full compliance. Whether you're monitoring SEO performance, tracking competitor updates, or analyzing content structure across multiple domains, we deliver tailored strategies that align with your specific goals.
Here’s how we make metadata collection more efficient:
- Build custom scripts for fast, scalable extraction.
- Automate metadata pulls across thousands of URLs.
- Organize Open Graph, title, and meta descriptions.
- Enable structured data mapping for advanced insights.
- Ensure continuous updates and maintenance.
- Comply with ethical and legal data practices.
From performance tracking to deeper digital audits, our scraping solutions are backed by expertise in Structured Metadata Collection, helping you make smarter decisions faster.
Conclusion
Extracting the correct metadata is no longer optional—it’s a core part of digital strategy. When you effectively Scrape Website Metadata, you unlock powerful insights that can improve everything from SEO performance to competitive positioning, all while saving time and resources.
With the rise of structured data and search personalization, Website Metadata Extraction 2025 plays a critical role in how content is understood and ranked. If you're ready to transform scattered metadata into a focused strategy, contact ArcTechnolabs today to start your customized solution. Let’s build more brilliant insights, one page at a time.







