
Introduction
In an age where businesses rely on real-time insights and large-scale data, conventional scraping setups are increasingly falling short. These traditional methods often falter under high demand, face throttling from target websites, or encounter access restrictions based on location. To address these limitations, organizations are shifting toward cloud-native scraping solutions that offer agility, reliability, and global reach.
By integrating serverless computing with robust cloud ecosystems like AWS, GCP, and Azure, teams can create a highly scalable, fault-tolerant scraping architecture that dynamically adapts to changing workloads. In this blog, we’ll explore how to design and scale Distributed Web Scraping using serverless functions across leading cloud platforms—redefining how data is efficiently harvested from the web.
Why Use Serverless Functions for Scraping?

Serverless functions provide a highly efficient way to execute web scraping tasks without the need to manage traditional infrastructure. Designed to be stateless and fast, they allow developers to concentrate solely on building and running the scraping logic. With seamless deployment across cloud platforms and regions, serverless functions offer both flexibility and scalability.
Key advantages include:
- Effortless auto-scaling to handle large-scale, concurrent scraping workloads.
- Minimal operational overhead—no virtual machines or container maintenance.
- Cost efficiency, with billing based strictly on execution time and resources utilized.
- Enhanced reliability and uptime when spread across multiple cloud regions.
By adopting a Serverless Web Scraping Architecture, organizations can create resilient, scalable scraping systems that respond to fluctuating data demands—without incurring unnecessary infrastructure costs.
Why Shift Your Scraping Infrastructure to Cloud Platforms?

Web scraping often involves unpredictable workloads — short bursts of intense activity, spread across multiple regions. Managing infrastructure for such variable demand can be complex and expensive. That’s where the cloud comes in.
By moving to cloud-native environments, teams can build systems that are scalable, responsive, and cost-effective. Cloud platforms enable you to run scrapers at scale without provisioning servers manually — ideal for bursty, parallelized operations.
Key benefits of moving to the cloud include:
- On-demand execution that dynamically scales with your workload.
- Built-in retry and monitoring mechanisms to ensure reliability.
- Cost-effectiveness — pay only for the resources consumed.
- Global deployment options to navigate around geo-blocks and throttling.
Building a Cloud-First Distributed Scraping Architecture
Building an efficient cloud-native scraping setup starts with a modular architecture and stateless execution. Your scraper should follow a micro-task pattern where each job—such as fetching, parsing, or storing—is broken down into lightweight, event-triggered components.
A robust Serverless Web Scraping Architecture includes:
- Function triggers include API Gateway (AWS), Pub/Sub (GCP), or Event Grid (Azure).
- Cloud storage for output, such as Amazon S3, Google Cloud Storage, or Azure Blob Storage.
- Queue mechanisms to manage scraping tasks efficiently.
- Logging and monitoring layers for observability and debugging.
Design your scrapers as granular units — fetch, parse, and store — to parallelize thousands of tasks simultaneously. This micro-tasking pattern enables truly cloud-native scraping operations.
Deploying Scraping Workflows on AWS: A Practical Approach
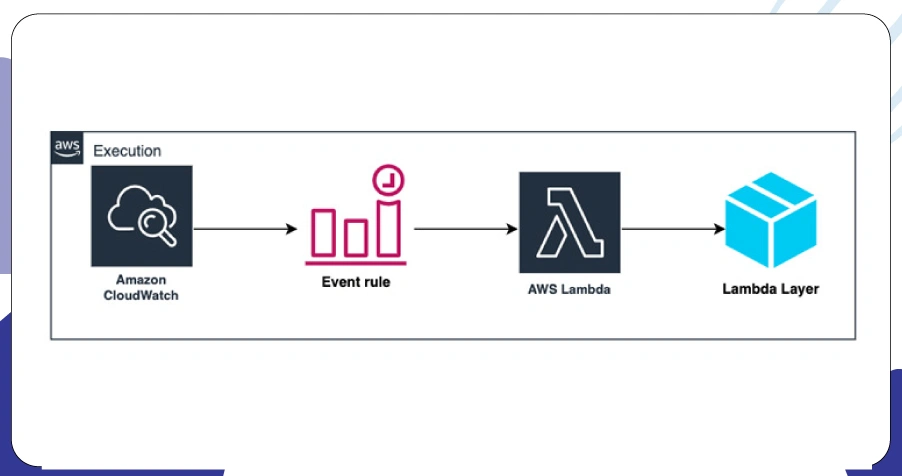
When it comes to reliability, maturity, and scalability, Amazon’s cloud stack is a top choice. AWS Lambda For Scraping allows you to execute scraping logic efficiently without managing backend servers.
You can build a scalable system using:
- Deploy Lambda functions to run scraping tasks asynchronously.
- Store scraped output in Amazon S3 for durability and easy access.
- Use Amazon SQS to queue thousands of target URLs across functions.
- Monitor executions and performance via CloudWatch.
With AWS, you get:
- Near-infinite scalability with zero server maintenance.
- Integrated IAM for secure, permission-based scraping.
- Regional function deployment to avoid IP throttling and regional blocks.
Web Scraping with Google Cloud Platform: Streamlined and Powerful
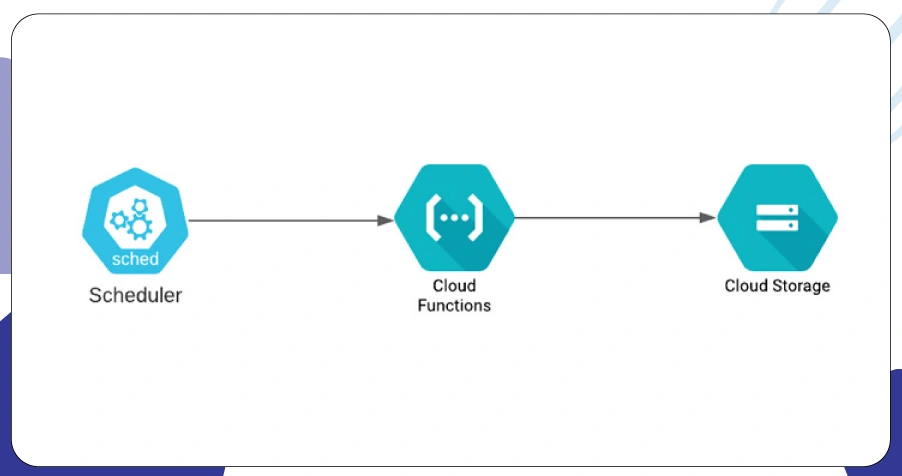
Organizations using GCP can benefit from a lightweight and efficient framework through GCP Cloud Functions Scraping. It supports rapid deployment and tight integration with Google's ecosystem.
What makes GCP powerful for scraping:
- Pub/Sub-based event triggers for streamlined task automation.
- Integrated secrets management for secure credentials handling.
- Multi-region deployment support for Multi-Region Web Scraping.
Additionally, scraped data can be loaded directly into BigQuery for near-instant analysis, making GCP a wise choice for data-intensive scraping projects.
Microsoft Azure: Enterprise-Ready Scraping Deployment

Microsoft’s cloud platform offers robust support for enterprise-level workflows. Using Azure Functions For Data Extraction, businesses can automate scraping jobs at scale with security and observability built in.
With Azure Functions, you can:
- Trigger scraping functions using HTTP endpoints or queues.
- Persist results in Azure Blob Storage for high durability.
- Use Application Insights to track performance, failures, and execution time.
This setup is especially ideal for:
- Enterprises requiring Microsoft compliance and ecosystem integration.
- Developers using .NET or C# for scraping logic.
- Projects using Active Directory authentication for internal access control.
Architecting for Scale: Beyond Serverless Functions
Building a scalable scraping engine isn’t just about deploying functions — it’s about how you manage their coordination. A Scalable Scraping Infrastructure focuses on intelligent orchestration.
Here's how:
- Use message queues like SQS (AWS), Pub/Sub (GCP), or Service Bus (Azure).
- Batch jobs into groups and trigger intelligently based on system load.
- Program smart rate limiting and retries to avoid overloading targets.
- Store transient state in scalable stores like DynamoDB or Firestore.
This orchestration turns your scraper into a distributed system—not just a collection of functions, but a scalable pipeline.
Mastering Parallelism in Cloud-Based Scraping

While high concurrency is essential for scraping speed, unmanaged parallel execution can result in IP bans, data loss, or duplicate work. Managing Parallel Scraping With Serverless takes careful tuning.
Best practices include:
- Use cloud NAT gateways or rotating proxies to manage IP hygiene.
- Implement throttling logic inside your functions to control concurrency.
- Organize scraping logic to avoid overlap and reduce wasted bandwidth.
These strategies ensure your scraper stays fast but under control—scaling smartly, not recklessly.
Going Global with Regionally Distributed Scraping

Geo-blocked or location-sensitive content is common across e-commerce, travel, and media platforms. If you're scraping at scale, Multi-Region Web Scraping is essential for speed, accuracy, and compliance.
Key tactics:
- Deploy serverless functions in multiple global regions.
- Capture localized versions of websites for richer insights.
- Blend data across regions to uncover geographic trends.
This improves not only scraping success rates but also unlocks location-specific analytics, which are critical for informed decision-making.
Automating Storage & Scheduling for Reliability

Two unsung heroes of Cloud-Based Web Scraping are automated storage and task scheduling. These components ensure your scrapers run consistently and data doesn’t get lost.
Recommended best practices:
- Persist all output in durable blob storage (S3, GCS, or Azure Blob).
- Use scheduling tools like AWS EventBridge, GCP Cloud Scheduler, or Azure Logic Apps to time scrapers.
Together, these systems guarantee that your scraping jobs are repeatable, traceable, and reliable — even as you scale.
Optimization & Security: Locking Down Your Scraper

With grand scale comes great responsibility. At an enterprise scale, even a minor inefficiency or security gap can have significant consequences. Following Serverless Scraping Best Practices ensures your systems remain robust and compliant.
Key practices:
- Store credentials using environment variables.
- Monitor and reduce cold start times for lower latency.
- Add detailed logging and alerting for anomaly detection.
- Properly handle cookies, CAPTCHA, and authentication flows.
- Keep your function payloads small to minimize delays.
Security and performance are not add-ons — they’re integral parts of every modern cloud-based scraping pipeline.
How ArcTechnolabs Can Help You?
We specialize in building robust Distributed Web Scraping systems that run seamlessly across AWS, GCP, and Azure. Whether you need large-scale data extraction or multi-region deployments, our solutions are designed for speed, flexibility, and reliability.
We offer:
- Custom scraper deployment across AWS Lambda, GCP, and Azure.
- Cloud setup optimized for high-concurrency and region-specific targeting.
- Lightweight scraper functions tailored for cost-efficiency.
- Full data pipeline integration with analytics tools.
- Maintenance, scaling, and compliance support.
Our team also ensures your system follows Serverless Scraping Best Practices to keep your infrastructure lean and future-ready. Let’s simplify your web scraping challenges—together.
Conclusion
As data demands grow, adopting a Distributed Web Scraping strategy offers the flexibility and scale today’s businesses need. With serverless technologies, you can extract data faster, smarter, and more efficiently—without the hassle of managing infrastructure.
Whether you're just starting or looking to expand your scraping capabilities, we can design a custom solution aligned with Serverless Web Scraping Architecture. Contact ArcTechnolabs today to schedule a complimentary consultation and take the first step toward achieving streamlined, scalable web scraping success.







